
长毛象中文实例信息图 (2021年3月)
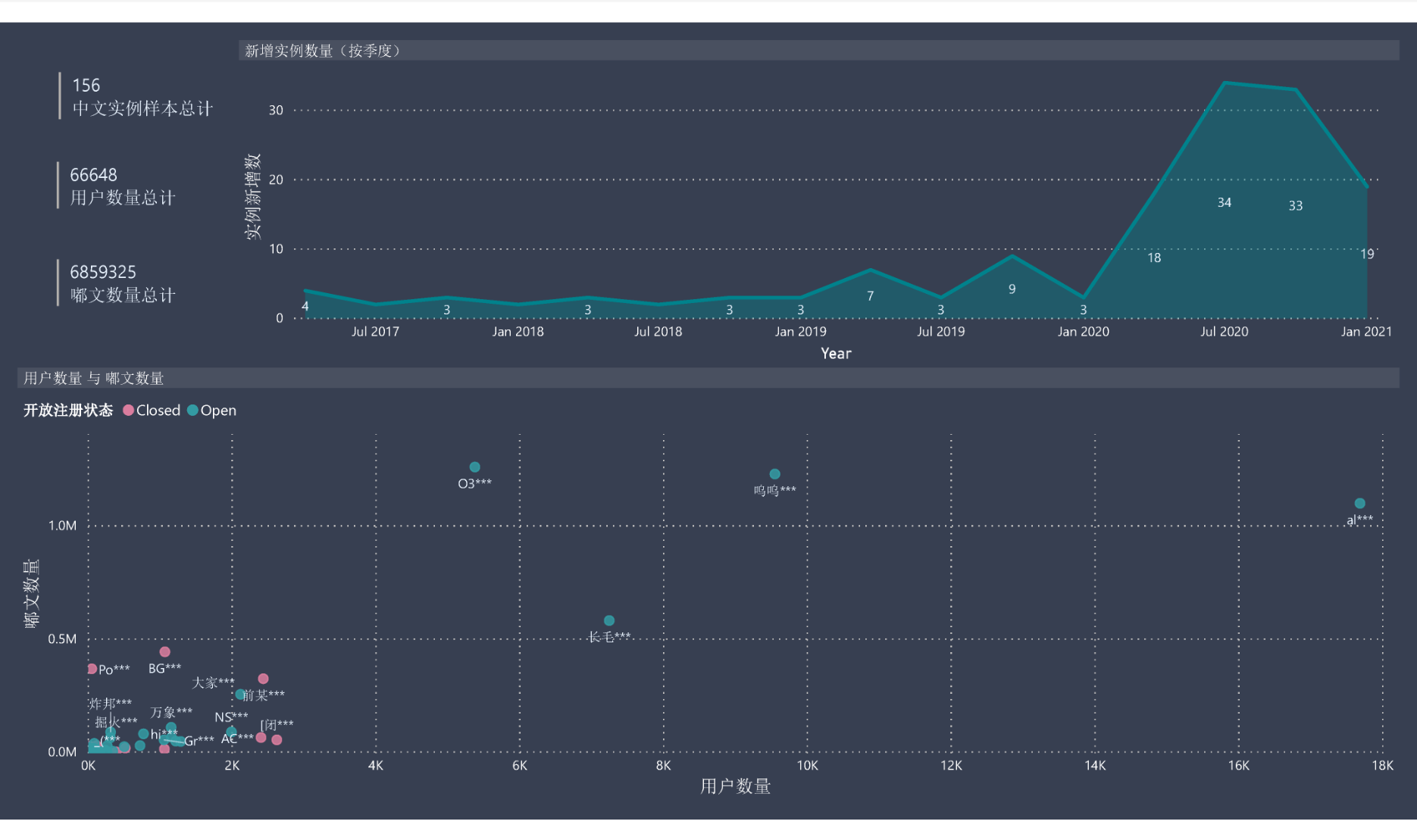
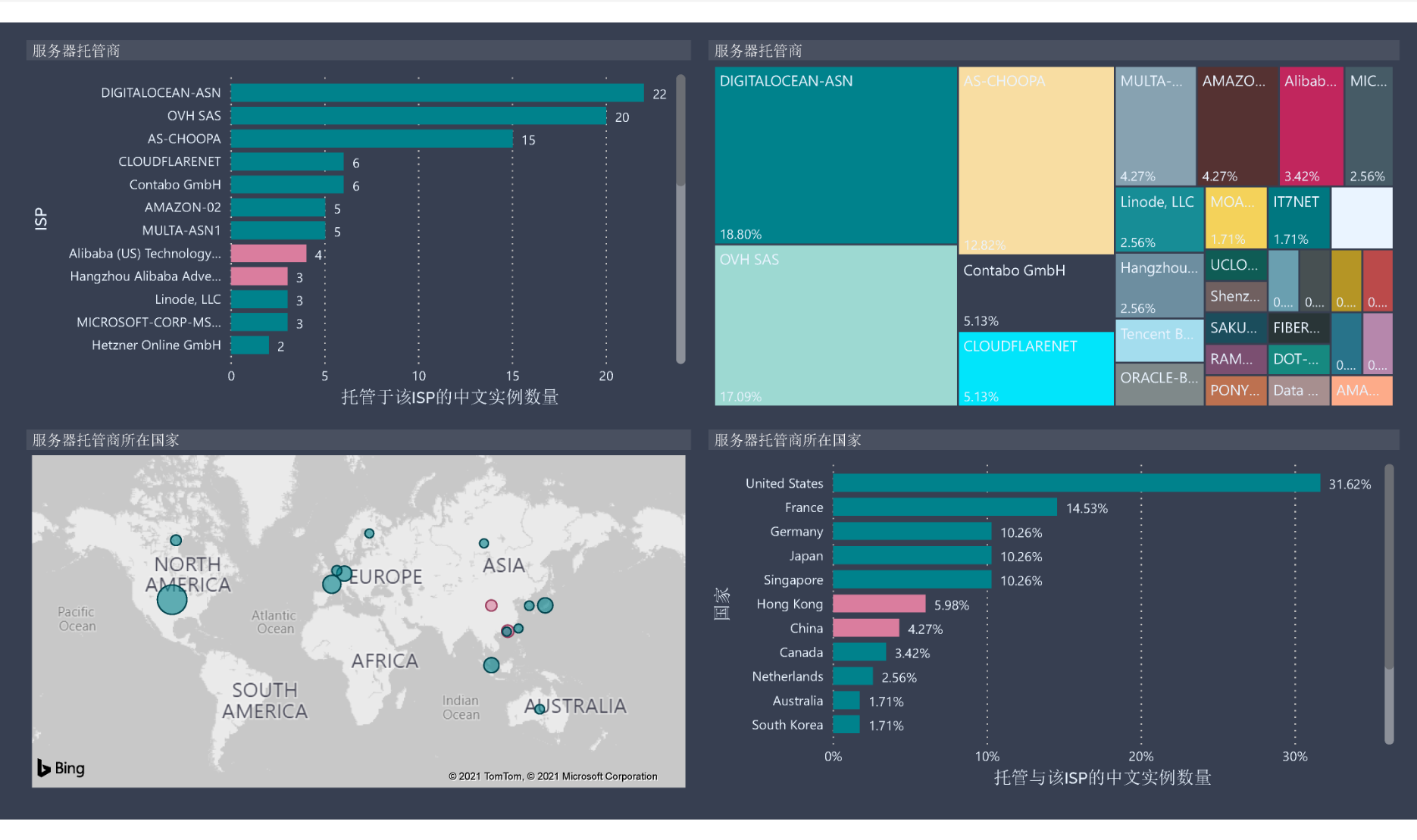
根据已知实例的 API 显示的公开信息,我们筛选出了 156 个现存的长毛象中文实例进行制图分析,结果高亮如下:
1. 近半中文用户集中在仅 3 个实例,中文毛象宇宙依然脆弱
2. 在 2020 年,长毛象宇宙喜提多个中文实例 ![]()
3. 约 38% 的中文实例未升级至去年底释出的最新版本 v3.3.0
4. 近半中文实例集中在 5 个服务托管商
5. 约 10% 的中文实例托管于中国大陆或香港 ![]()

Follow

{kind=link}
{kind=link}
{kind=link}
{kind=link}
确实如此,在我自建实例之后就发现这个缺点显得尤为突出,比起自建一个容纳几十人的站,在加入了中继的大站注册显然能看到更多信息。如果只依靠自己的实例,很多人的 profile 根本就看不全,需要依靠主页查看,而里瓣的「茫然一片」和诸多实例加上的「只限十条」等技术补丁进一步加大了检视新用户过往发言的难度。所以最后即使自建或者加入更小更新的实例,依然要依靠在大站的帐号才能较为充分地探索,像活吧、嘟站、草莓县这样几乎和所有实例互通,流入了庞大数据的站点,就更会成为用户集中的趋向点了。
